Intention Recognition
Trainable software for recognizing and utilizing interaction between humans, objects, and digital interfaces.
Intention Recognition (IR) is an intuitive interaction-to-interface software, exposed as a streaming API. Using computer vision and machine learning it detects objects and gestures to control digital interfaces.
IR removes the need for peripheral devices such as keyboards, mouses, and touchscreens. With it, you can turn any space into a physical-digital hybrid environment. Physical interactions controlling digital interfaces.
Combining physical artifacts with digital interfaces opens up a new space for many situations. Pick up a book in the library and receive extra relevant information. Work with physical archive material that is directly connected to its digital inventory system.

IR is trainable software that detects gestures and actions. Both the gestures and actions a human makes and the gesture and actions a human does with a particular object. IR can be trained by feeding it visual information of the objects it needs to detect. This way IR is fit for any situation and remains fast for each purpose.
In IR we make a distinction between gestures and actions. Gestures are simple single queues such as a fist or holding your hand with only an extended index finger. Actions are more complex as they are a sequence of gestures and only a specific sequence makes an action. For humans though actions are really simple such as waving your hand or making a sweeping movement. IR can be trained to recognize specific gestures and actions as well.
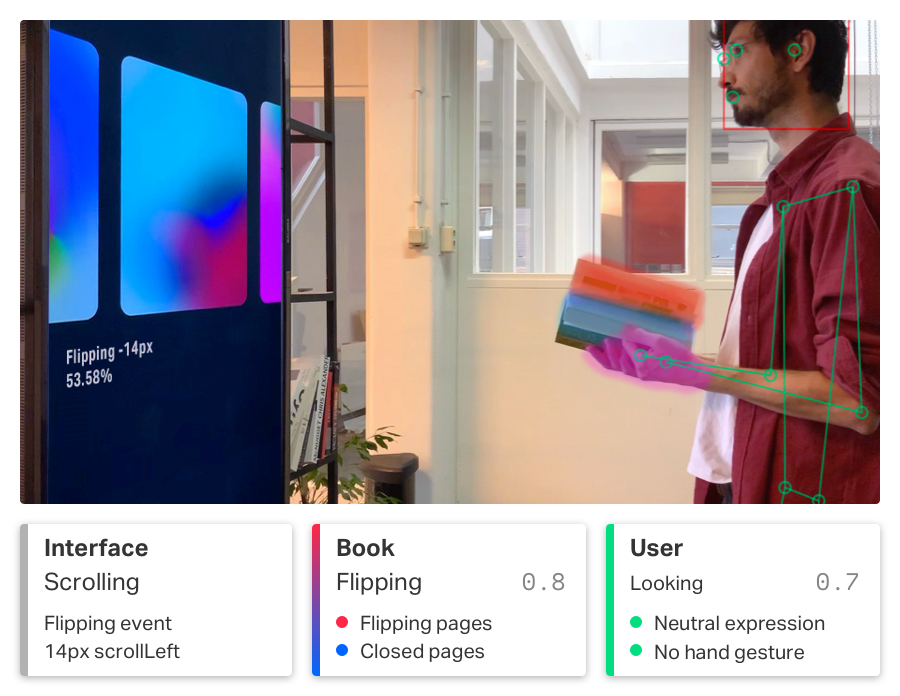
Besides recognizing objects and humans moving we’ve built IR to recognize the interaction between the human and the object. Creating a powerful addition to the possible gestures and actions it can detect. Your physical interaction with objects becomes directly linked to digital interaction.
IR is easily implemented in any modern framework using its streaming API. Fetching and querying is reliable and fast making the API fit in all sorts of applications, be it websites, digital catalogs, or mobile applications.
Features
-
Gesture and action recognition
IR recognizes simple gestures and complex actions which can be used to control digital interfaces. The nature of gestures and actions can be of any type: hand, feet, or full body.
-
Human-with-object interaction
The way someone interacts with an object is very specific to both the type of object and the intent of the person. Be it skimming through a book or holding a wine bottle.
These interactions are meaningful and can be augmented with our digital systems through IR. IR allows for defining specific human-with-object interactions so that those can be utilized to control an interface.
-
Trainable and customizable
IR can be trained on specific objects, human gestures/actions, and human-with-object gestures/actions. This feature makes IR ideal for very specific situations and stays optimized for each job.
-
Almost zero hardware needed
IR comes in a very compact package and works with any regular, budget, or embedded camera. It also makes a range of standard hardware unnecessary such as keyboards, mouses, touchscreens, depth-cameras, sensors, and other peripheral devices.
-
Local off-the-grid
IR can be installed locally without using the API when stable connections are not guaranteed. This will however slightly increase the hardware needed and require a power source. Ideal for unique situations such as public installations.


How it works
Intention Recognition’s architecture is split into two endpoint groups. Each is concerned with a particular geometry.
The two endpoint groups don’t have a specific order but the first group is for human-action detection and classification. In this group, we have a machine learning model to detect and learn new actions performed by humans. We have two endpoints designed for this group, a hand-based endpoint, and a facial-based endpoint.
The other group is the human-asset-action detection and classification group. Here our machine learning model is located to detect a defined object and actions done with that object. For this group, we have one endpoint.
Each endpoint can be used with a special state, called observer mode. This mode sets IR in observation mode in which IR keeps observing the incoming input. Incoming non-predefined actions are classified and can be used after the observation. This mode is great for an intuitive approach without the need to follow predefined actions and gestures.
Both endpoint groups receive video input using WebRTC (for improved performance) and analyze the sequence of frames to detect an action.

Roadmap
April 2020
Designing software architecture
Key for having robust and optimized software.
June 2020
Building collection of training datasets
12+ datasets and around 100,000 labeled entries both in videos and images.
July 2020
Deployment of models
Seeing the result of all the training.
August 2020
Further training
Both our action model and object-interaction model needed more training.
April 2021
Opening API (beta) demo registration form
June 2021
Designing and development API (beta) interface
August 2021
Exclusive release beta version for registered customers
September 2021
Retrieving feedback from the beta release
October 2021
Development API (v1.0.0)
February 2022
Launch of API v1.0.0
Team
Amir Houieh @suslib.com
Co-founder and developer
Martijn de Heer @suslib.com
Co-founder and designer
Homayuon Moradi
Computer vision engineer
Ada Popowicz
Designer, intern