Knowledge Recognition
Flexible software for transforming any collection into a semantically meaningful and contextually networked library.
Knowledge Recognition (KR) is a knowledge extraction software that comes in both a REST and streaming API. It uses machine learning to extract complex information from any digital asset.
With KR any collection can be transformed into a dense network with a deeper semantic understanding of each asset and the contextual relationship between them.
Search semantically through your collection. Group its assets based on extracted topics. Detect smiles and body poses. Traverse between assets based on their similarity or matching web videos.
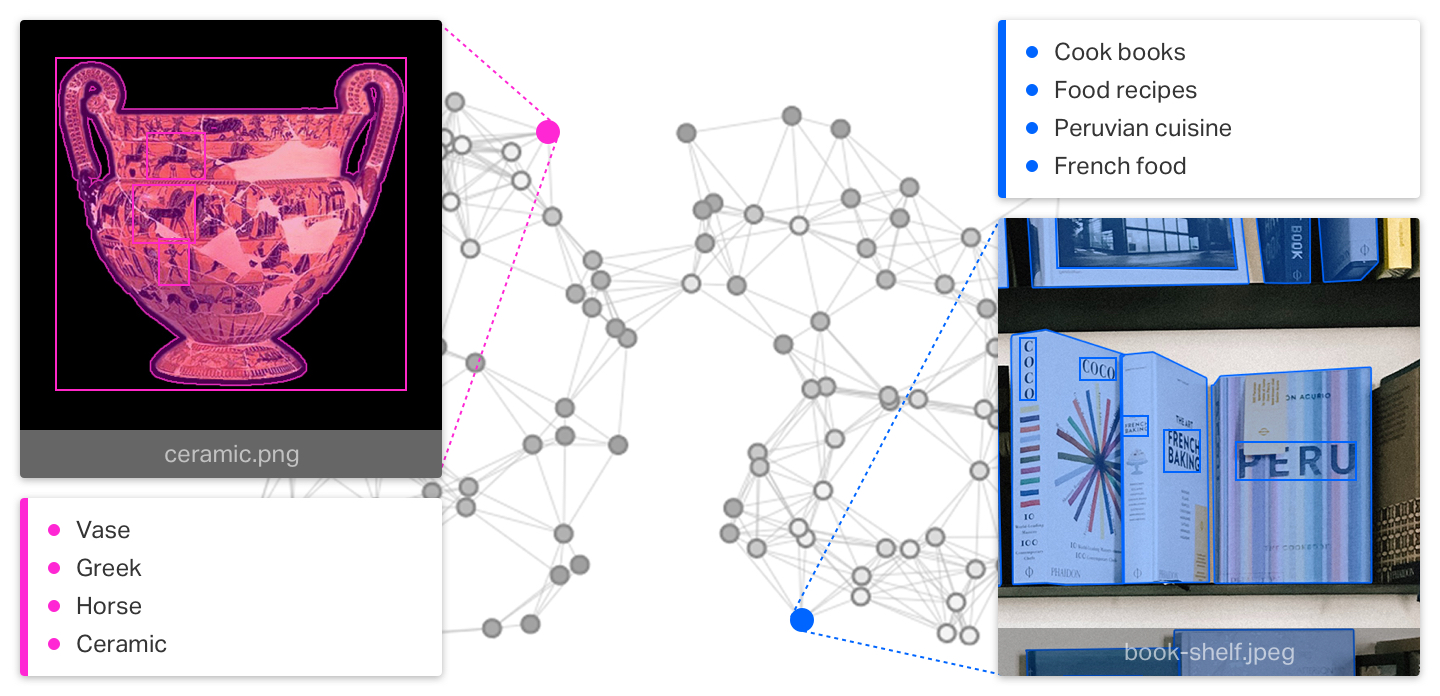
KR takes in files and has unique processes for visual and textual input. These unique processes use machine learning, computer vision, and natural language processing algorithms to gather data from the input. After this extraction process, the extracted data is analyzed and processed again to build a higher understanding of its contents.
Each asset of a collection is “enhanced” in this process and after it will have enriched metadata. Besides the extra acquired information about itself, it will also contain information about other assets it has direct or strong relations with. This contextual awareness is exciting as it reveals new connections within a collection and makes it much easier to traverse between assets.
All of this is easily implemented in any modern framework using either the REST or streaming API. Fetching and querying is reliable and fast making KR fit in all sorts of applications, be it websites, digital catalogs, or mobile applications.
Our application IAA uses KR as its backbone technology.
Features
-
Visual context extraction
For extracting information from images KR uses processes such as, but not limited to:
- image labeling;
- physical attributes extraction;
- instance and semantic image segmentation;
- content block segmentation; and
- optical character recognition.
-
Textual context extraction
For extracting information from text KR uses processes such as, but not limited to:
- entity extraction;
- topic extraction;
- keyword extraction;
- linguistic character analysis; and
- automatic summarization.
-
Multidimensional context
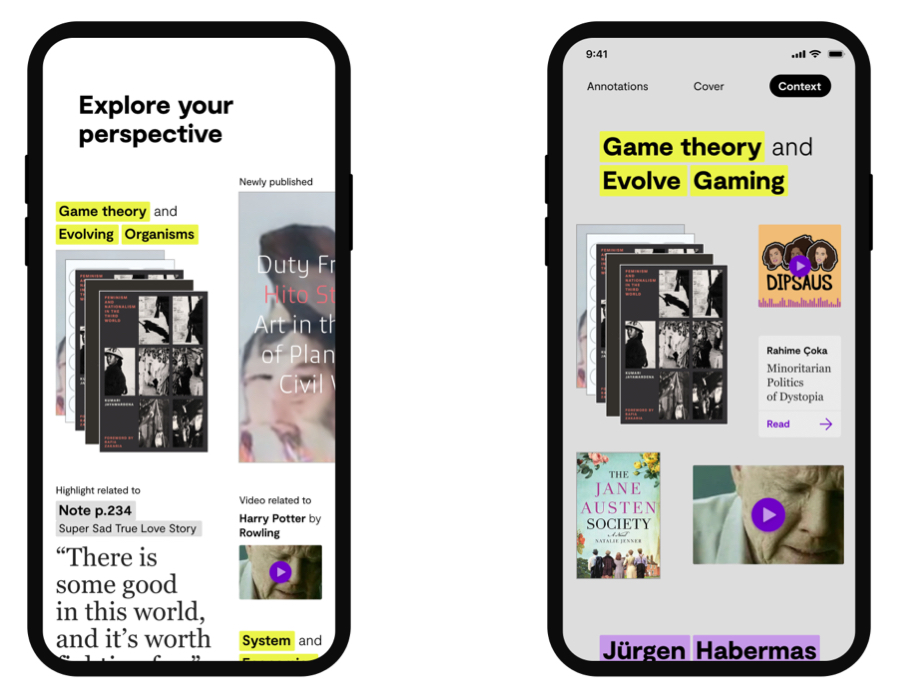
By combining the extraction processes KR can create a contextual view of a collection. The basis of the context however can be a range of variables also based on prior processes, therefore it's multidimensional. The context also contains connections to outside the collection with defined webhooks. For instance to include YouTube, SoundCloud, or Wikipedia.
Our application Field, seen here on the right, uses this feature to its advantage, having a contextual view also based on user preference.
-
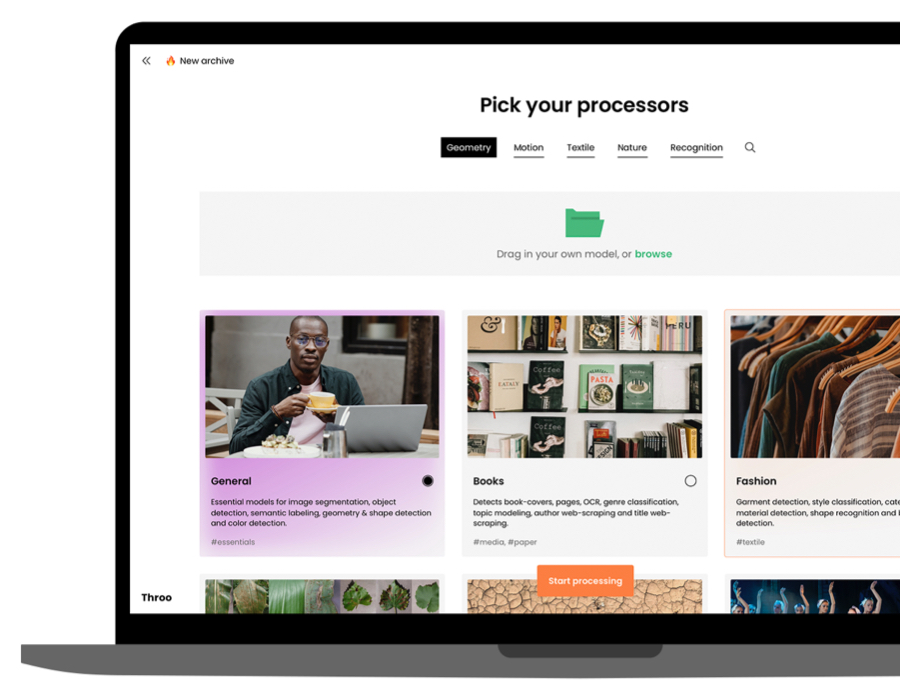
Flexible and modular
KR comes with pre-trained AI models and an easy process to pick which modules are needed for your situation. Ideal for quick and easy implementation and keeping things efficient, as no unnecessary processes are used.
KR can be expanded, however! Using your customized models and setting up unique endpoints. Making KR very versatile and its application boundless.
-
Queryable and lightning-fast
Implementing and using KR is made easy and fast with RESTful queries. Simply put a query in the request URL to get the needed result.
The streaming API is perfect for lightning-fast response time, ideal for a bigger project where a steady connection is guaranteed or instant response is required.
-
Not a CMS but a slice in between
KR can easily be implemented to work in any infrastructure or with any software. It's best viewed as a thin layer of software that sits in-between a CMS and a database. This makes it easy to implement while not making it a dedicated pillar of your system.
-
Sharing extracted knowledge
Through KR it is possible to share the enriched metadata KR extracts with other KR users. This shared repository can be useful when two parties have the same assets. Especially when thinking of descriptional texts or categorization this can improve the time spent.
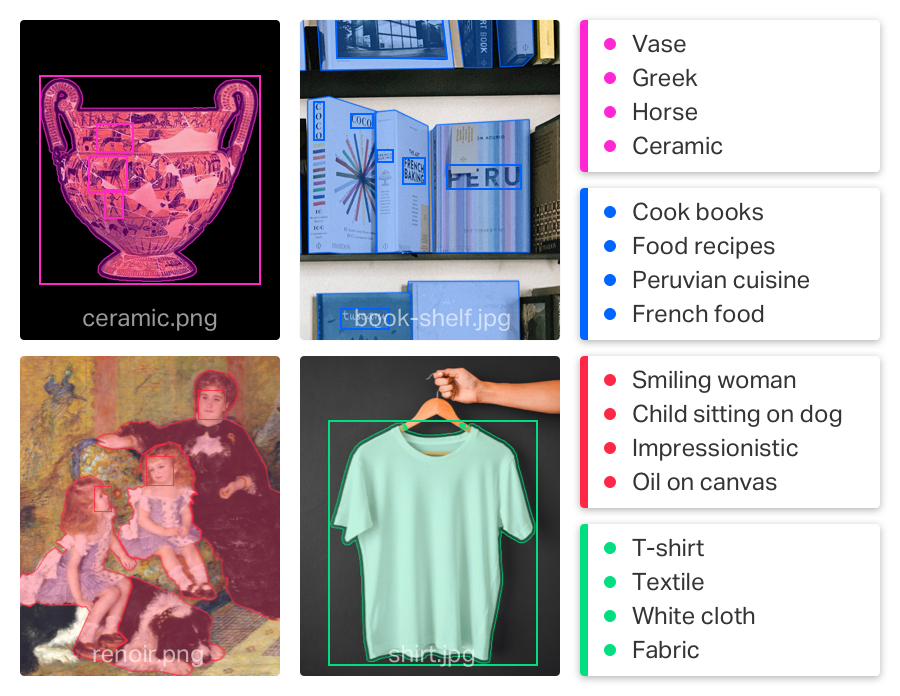


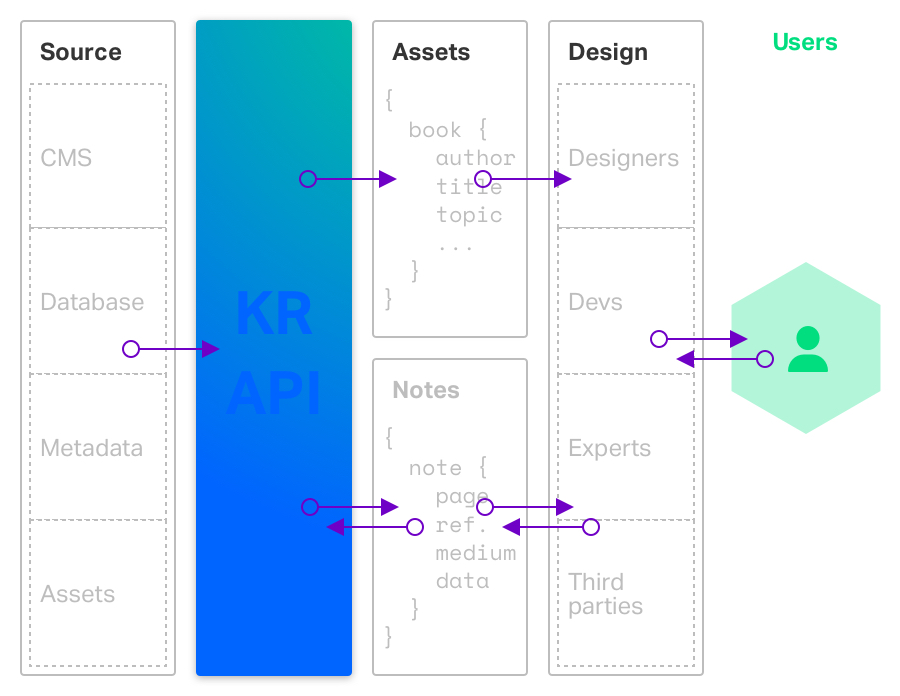

How it works
Knowledge Recognition’s architecture is split into two layers. Each consists of several modules concerned with its layer’s task.
The first layer of KR is the extraction layer. This layer is responsible for extracting all the information from the given input. The modules in this layer analyze the given input using various deep learning models such as pose detection, optical character recognition, object detection, and instance labeling. These modules can be chained and reiterated so that a text detected in an image can then be analyzed for entity recognition for example.
The second layer of KR is the contextualization layer. Here the software takes all the gathered data from the first layer (enriched metadata) and performs additional processes. The second layer allows KR to search specific web-based platforms – such as Wikipedia or SoundCloud – for related content.

Roadmap
April 2020
Designing software architecture
Key for having robust and optimized software, with the split layers we have achieved a solid solution.
May 2020
Development prototypes
Preparing training datasets for different machine learning models and setting up the architecture.
June 2020
Testing prototypes
Prototypes are working and using both Field as IAA to test them.
July 2020
Development API (beta)
Both the REST and the streaming API.
October 2020
Designing and development API (beta) interface
Organizing all the features and output in an effective interface helps a lot with seeing the results.
April 2021
Opening API (beta) demo registration form
Opening forms for people to request a demo for the API.
August 2021
Exclusive release beta version for registered customers
May 2021
Retrieving feedback from the beta release
June 2021
Development API (v1.0.0)
August 2021
Launch of API v1.0.0
Team
Amir Houieh @suslib.com
Co-founder and developer
Martijn de Heer @suslib.com
Co-founder and designer
Homayuon Moradi
Computer vision engineer